Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databasesを読む(その4 THE LOG MARCHES FORWARD)
4 THE LOG MARCHES FORWARD
ここでは、永続状態、実行状態、レプリカ状態で常に一貫しているように、データベースエンジンからどのようにログが生成されるかを説明する。(3つの状態があるってことか)
特に、コストが高い2PC(2 phase commit)のプロトコルを使わずに、効率的に一貫性を保つ実装方法を述べる。
(データ指向アプリケーションデザイン p 386あたりを参照する)
まず、クラッシュリカバリー時におけるコストの高いredo処理を回避する方法を示す。
次に、通常の運用時と、実行状態とレプリカ状態の維持の方法を説明する。
最後に. リカバリー処理の詳細を示す。
補足の資料を用意してあります。
4.1 解決策の全体像 : 非同期処理
セクション3で説明したように、Auroraではデータベースをredoログストリームとしてモデル化しているので、このredoログが順序だった変更の連続の流れという事実を利用することができる。
実際には、各ログレコードには関連するログシーケンス番号(LSN)があり、これはデータベースによって生成された単調増加する値である。 (MySQL InnoDBのpageの中にあるLSN(Log Sequence Number)は増加し続ける値で、InnoDBがredoログに50バイト書き込めば、LSNも50バイト進むようになっています。)
https://dev.mysql.com/doc/refman/5.6/ja/glossary.html#LSN
これにより、やり取りが多く失敗に不寛容な2PCのようなプロトコルの利用なしに、非同期的なアプローチにより状態を維持するための合意プロトコルを単純にできる。
高レベルでは、ある時点での一貫性と耐久性を維持し、未処理のストレージ要求に対するackを受けとりつつ、維持できているポイント継続的に進めていきます。
個々のストレージノードは、1つ以上のログレコードをロストしているかもしれないので、PGの他のメンバーとgossip protocolでやりとりしてギャップを探してロストした分を埋めていく。
状態が失われて再構築しなければならないリカバリ時を除き、データベースによって維持される実行状態( runtime state )においては、クオラムリードではなく一つのセグメントリードを使うことができる。
データベースには複数の未処理の分離されたトランザクションがあり、それらは開始された順序とは異なる順序で完了(完了して耐久性のある状態に到達)する可能性がある。(並行性の問題)
データベースがクラッシュしたり再起動する場合、ロールバックするかどうかの判断は、個々のトランザクションごとに別個に行われる。
(MySQLの例はこれ MySQL :: MySQL 8.0 Reference Manual :: 15.18.2 InnoDB Recovery)
中途半端なトランザクションを追跡し元に戻すロジックは、単純なディスクへの書き込み(つまりcommitのロジック?)と同様に、データベースエンジンに実装されている。
しかし、再起動時において、Auroraのデータベースは、ストレージボリュームへのアクセスが発生するより前に、ユーザーレベルのトランザクションを見ない、ストレージサービスで独自のリカバリを行う。
このストレージサービス独自のリカバリは、分散された性質にもかかわらず、データベースにストレージのビューが全て同じように見えるようにする。
ストレージサービスは、すべてのログレコードの可用性を保証できる一番大きいLSNを決める(これはVCLまたはVolume Complete LSNと呼ばれる)。
ストレージのリカバリ中に、VCLより大きいLSNを持つすべてのログレコードは削除しなければならない。
しかし、データベースは、ログレコードにタグを付け、CPL(Consistency Point LSN)として識別することで、削除が可能なポイントのサブセットをさらに限定できる。
そこで、VDL(Volume Durable LSN)をVCLより小さいが最も大きいCPLと定義し、VDLより大きいLSNを持つ全てのログレコードを削除する。
たとえば、LSN 1007までの完全な( Completeな )データがあるとして、データベースは900、1000、1100がCPLであると宣言しているとしたら、その場合は1000以上で切り捨てる必要がある。
1007までは完全( Complete )で、1000までは耐久性(Durable)がある。
完全性と耐久性は異なるものであり、CPLは、順番に受け入れなければならないストレージシステムのトランザクションのいくつかのまとまりについて線引きするものと考えることができる。
クライアントがこのような区別を必要としない場合は、単純にすべてのログレコードをCPLとしてマークすることができる。
ただ、実際には、データベースとストレージは以下のように相互作用する。
- 各データベースレベルのトランザクションは、順序付けられた複数のミニトランザクション(MTR)に分割され、 アトミックに実行される必要がある
- 各MTRは、連続する複数のログレコード(必要な数だけ)で構成される
- MTRの最終ログレコードは CPL である。
- 予想ですが、MTRのstateから判別しているのでは?と思っています。 https://dev.mysql.com/doc/dev/mysql-server/latest/mtr0types_8h.html
リカバリ時には、データベースはストレージサービスとやりとりして各PGの耐久性(PGCL)を持っているポイントを集め、それを利用してVDLを作り、VDL以上のログレコードを切り詰めるコマンドを発行する。
4.2 通常の動作
ここでは、データベースエンジンの「通常の動作」について、書き込み、読み込み、コミット、レプリカに焦点を当てて説明する。
4.2.1 書き込み
書き込みの流れの概要図をはっておく。
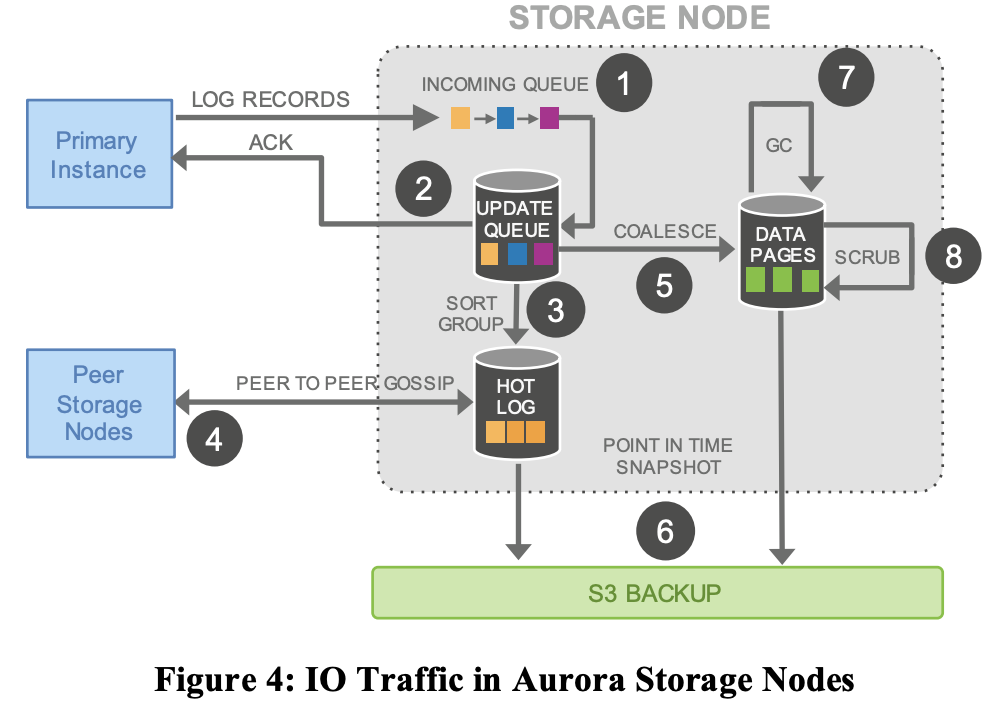
Auroraでは、データベースはストレージサービスと継続的にやり取りし、クオラムの確立、ボリュームの耐久性の向上、コミットされたトランザクションの登録ができる状態を維持する。
例えば、通常時(ログが前進する)のフローだと、データベースがログレコード群の書き込みクオラムの成立のackを受け取ると、現在のVDLを進める。
任意の時点で、データベースではトランザクションが並行して発生しており、それぞれが独自のredoログレコードを生成している。
データベースは、現在のVDLとLSN Allocation Limit(LAL)と呼ばれる定数(この時点では1000万)の合計よりも大きい値を持つLSNは存在しないという制約で、各ログレコードに一意で順序だったLSNを割り当てる。
この制限は、ストレージシステムにないログがデータベースシステム上に増えすぎないようにし、ストレージやネットワークが追いつけない場合には書き込みを制限にすることができるバックプレッシャーが かかる。
各PGの各セグメントは、そのセグメントに存在するページに影響を与えるボリュームの中のログレコードの一部部分のみを見ている。
各ログレコードには、そのPG内の以前のログレコードを識別するための被リンクが含まれている
これらのバックリンクは、各セグメントに到達したログレコードの完全性のポイント(PGが受信した全てのログレコードのうち各セグメントの最大のLSN(Segment Complete LSN (SCL)))を追跡するために使用される。
SCLは、各ストレージノードが 不足しているログレコードを見つけ、交換するためのgossip protocolでのやりとりに利用される。
4.2.2 コミット
Auroraでは、トランザクションのコミットは非同期に完了する。
クライアントがトランザクションをコミットすると、コミットリクエストを処理するスレッドは、トランザクションを コミットを待つ別のトランザクションのリストの一部として "コミットLSN" を記録することで処理を完了させて、他の作業を実行する。
最新のVDLがトランザクションのコミットLSN以上である場合に限りコミットを完了することがWALプロトコルと同等のものとなる。
(データ指向アプリケーションデザイン p 170)
VDLが進むと、データベースはコミットを待っている正しいトランザクションを特定し、専用のスレッドを利用して待機中のクライアントにコミットのackを送信する。
ワーカースレッドはコミットのために一時停止せず、単に保留中の他のリクエストをとってきて処理を継続する。
4.2.3 読み取り
Auroraでは、多くのデータベースと同様に、ページはバッファキャッシュから提供され、当該ページがキャッシュに存在しない場合にのみストレージIOリクエストが発生する。
バッファキャッシュがいっぱいになると、システムはキャッシュから退避させるためのページを見さがす。
従来のシステムでは、犠牲となるページが「ダーティページ」であった場合、そのページを後から取得しても常に最新のデータが得られるようにするため、置き換わる前にディスクにフラッシュさる。(MySQLの場合は 詳解MySQL 5.7 p 127参照)
Auroraデータベースは、退避時やそれ以外であってもにページを書き出すことしないが、バッファキャッシュ内のページは常に最新バージョンになることを強く保証している。
これは、ページに対する最新の変更に関連するログレコードを識別するためのpage LSNがVDL以上の場合においてのみ(only ifって書いてある)キャッシュからページを退避するという実装によって実現されている。
(この実装だと、古いページキャッシュが残り続けてキャッシュを圧迫しそうなのでLRUもあると思うが、Auroraにおけるページキャッシュのevictionに関しては、記述はこの論文しか見当たらず、これだけのevictionかどうかわからない。。。。)
このプロトコルは以下のことを保証している。
- ページ内のすべての変更がログに固まっている
- キャッシュミスの際、最新の耐久性のあるバージョンを取得するためには、現在のVDLの時点でのページのバージョンを要求すれば十分であること
通常の状態では、データベースは読み取りクオラムを使用してコンセンサスを確立する必要はない。
ディスクからページを読み取る場合、データベースはリクエストが発行された時点のVDLを表す読み取りポイント( read-point )を確立する。
その後、データベースは読み取りポイントに対して完全(complete)であるストレージノードを選択し、その結果、最新のバージョンを受け取ることができる。
ストレージノードから返されるページは、データベース内のミニトランザクション(MTR)の期待される形式と一致していなければならない。
データベースは、ストレージノードへのログレコードの提供と、進捗状況の追跡を直接管理している(各セグメントのSCLなどのこと)ので、通常ならば読み取りを満たすことができるセグメント(SCLが読み取りポイントより大きいセグメント)がわかり、十分なデータを持つセグメントに直接読み取り要求を発行することができる。
データベースは未処理の読み取りをすべて監視しているので、PGごとに最小の読み取りポイントLSNをいつでも計算することができます。
リードレプリカがある場合、ライターはそのレプリカとgossip protocolでやり取りして、すべてのノードでPGごとの最小の読み取りポイントLSNを作る。
この値はPGMRPL(Protection Group Min Read Point LSN)と呼ばれ、あるPGのすべてのログレコードが不要となる"低水位"(底)を表す。
言い換えれば、ストレージノードセグメントは、PGMRPLよりも低い読み取りポイントを持つ読み取りページ要求が存在しないことが保証される。
各ストレージノードはデータベースからPGMRPLを認識しているため、古いログレコードを合体させ、安全にGCすることで、ディスク上の実体化されているページを前に進めることができます。
また実際の並列制御のプロトコルは、従来のMySQLのように、ページとUndoセグメントがローカルストレージに構築されているのとまったく同じようにAuroraのデータベースエンジンで実行される。
4.2.4 レプリカ
Auroraでは、1台のライターと最大15台のリードレプリカが、1つの共有ストレージボリュームをマウントすることができる。
そのため、リードレプリカを追加しても、消費されるストレージやディスクの書き込み操作による追加コストは発生しない。
遅延を最小限に抑えるために、ライターで生成されストレージノードに送信されるログストリーム(redoログのストリームってことかな)は、すべてのリードレプリカにも送信される。
リーダーでは、データベースが各ログレコードの順序を考慮しながらログストリームを消費する。
ログレコードがリーダのバッファキャッシュ内のページを参照している場合(更新系の処理ってことかな)は、ログアプリケータを使用してキャッシュ内のページに指定されたredoログの操作を適用する。
それ以外の場合は単にログレコードを破棄する。
レプリカとは関係なくユーザーコミットをackするライターの観点からだと、レプリカはログレコードを非同期に消費することに注意する。
レプリカがログレコードを適用するときには下記の2つの重要なルールに従う。
- LSN がVDL以下のログレコードだけが適用される
- レプリカがすべてのデータベースオブジェクトの一貫したビューを見ることができるようになるために、1 つのMTRの一部であるログレコードはレプリカのキャッシュの中でアトミックに適用される
(アトミック: データ指向アプリケーション p242あたりを参照)
実際には、通常、各レプリカはライターから短い間隔(20ms以下)で遅れている。
4.3 リカバリ
従来のデータベースの多くは、ARIESなどのリカバリプロトコルを使用しており、コミットされたすべてのトランザクションの正確な内容を表すことができるWAL (Write-ahead Log)の存在に依存している。
また、これらのシステムでは、ダーティページをディスクにフラッシュし、ログにチェックポイントレコードを書き込むことで、定期的にデータベースのチェックポイントを作成し、荒い粒度ではあるが耐久性が保証されているポイントを確立する。
www.slideshare.net
再起動時には、どのページにもコミットされたデータの欠損、コミットされていないデータが含まれている可能性がある。
そのため、クラッシュリカバリー時には、ログアプリケーターを使って、最後のチェックポイント以降のredoログレコードを処理し、各ログレコードを対象のデータベースページに適用する。
このプロセスにより、データベースページは障害発生時点における一貫性がある状態に戻るので、その後、undoログレコードを実行することで、クラッシュ中で実行中のトランザクションをロールバックすることができる。
MySQL :: MySQL 5.6 リファレンスマニュアル :: 14.16.1 InnoDB のリカバリプロセス
(詳解MySQL 5.7 p 121 p 142)
クラッシュリカバリーはコストが高い作業である。
チェックポイント作成の間隔を短くすると効果的ですが、フォアグラウンドのトランザクションと干渉してしまう。
Auroraではそのようなトレードオフは必要ない。
従来のデータベースの一つ単純な原則は、フォワード処理パスでもリカバリーでも同じredoログアプリケータが使われ、データベースがオフラインの間は、同期的にフォアグラウンドで動作する。
Auroraでも方針は同じだが、redoログアプリケーターはデータベースから分離され、ストレージノード上で並列に、常にバックグラウンドで動作する。
そのため、データベースが起動すると、ストレージサービスと連携してボリュームリカバリーを実行するのだが、Auroraデータベースは1秒間に10万件以上の書き込み処理しているときにクラッシュしても、非常に素早く(通常は10秒以下)回復することができる。
クラッシュ後は、データベースはランタイム状態に再構築する必要がある。
この場合、データベースは各PGごとに、書き込みクオラムに到達した可能性のあるデータの検出を保証するのに十分なセグメントの読み取りクオラムを確立する。
(ここで読み取りクオラムが使われる!!!!)
Amazon Aurora Storage Demystified: How It All Works (DAT363) - AWS re:Invent 2018 from Amazon Web Services
www.slideshare.net
データベースは、すべてのPGに対して読み取りクオラムを確立すると、VDLを再計算(VCLより小さいが最も大きいCPL)し、新しいVDL(Volume Durable LSN)以降のすべてのログレコードを削除する切り捨て範囲を生成する。
(ここでVDLと書いてあるが、別の論文だとVCLってあったりして混乱する、VDLが正しいと思う)
Amazon Aurora Storage Demystified: How It All Works (DAT363) - AWS re:Invent 2018 from Amazon Web Services
www.slideshare.net
データベースが証明できる最終LSNは、これまでに見られた可能性のある最も先の未処理ログレコードと少なくとも同じ大きさである。
データベースがLSNを割り当てており、VDLを超えて割り当てられるLSNの範囲を制限している(1000万の制限)ため、この上限を推定する。
切り捨て範囲はエポック番号でバージョン管理され、ストレージサービスに永続的に書き込まれる。
これにより、リカバリが中断されたり再開されたりしても、切り捨ての耐久性について問題はなくなる。
クラッシュリカバリー後の新たなredoレコードには、切り捨て範囲以上のLSNが割り当てられる。
( http://pages.cs.wisc.edu/~yxy/cs764-f20/papers/aurora-sigmod-18.pdf 2.4 Crash Recovery in Aurora 参照)
データベースは、クラッシュリカバリーの一環としてredoのリプレイは必要はないが、クラッシュ時に実行中のトランザクションの操作を元に戻すために、undo リカバリーを行う必要がある。
しかし、undoリカバリーは、システムが、undoセグメントから実行中のトランザクションのリストを構築した後、データベースがオンラインになったときにアクティブだったトランザクションの取り消しを行う。
参照
- page cache周り
www.slideshare.net