Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databasesを読む(その5 PUTTING IT ALL TOGETHER)
5 PUTTING IT ALL TOGETHER
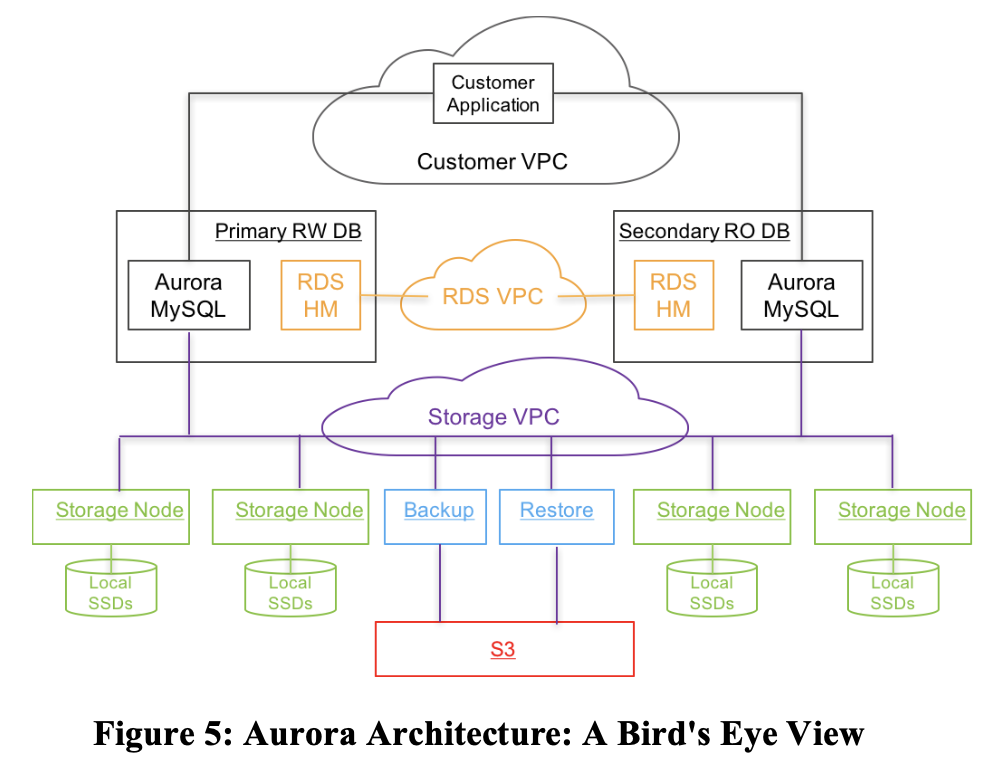
ここでは、Figure 5で示すAuroraの構成要素について説明する。
https://www.allthingsdistributed.com/files/p1041-verbitski.pdf 参照
データベースエンジンは "community" MySQL/InnoDBのフォークであり,主にInnoDBがどのようにデータをディスクに読み書きするかで変わる。
"community" InnoDBでは、書き込み操作によってデータがバッファページで変更され、関連するredoログレコードがLSN順にWALのバッファ(メモリ)に書き込まれる。
トランザクションのコミット時には、WALプロトコルは、トランザクションのredoログレコードが永続的にディスクに書き込まれることのみが必要になる。
実際に変更されたバッファページは、中途半端なページ書き込みを避けるために、ダブルライトで最終的にディスクに書き込まれる。
これらのページの書き込みは、バックグラウンドや、キャッシュからの退避中、チェックポイントの取得中に行われる。
InnoDBには、IOのサブシステムのほかに、トランザクションサブシステム、ロックマネージャー、B+-Treeの実装、「ミニトランザクション」(MTR)の概念が含まれている。
MTRは、InnoDB内部でのみ使用されるもので、アトミックに実行されなければならない一連のオペレーションを表現したものである(例:B+ ツリーのページ分割/マージとか)。
(詳解MySQL 5.7 p 124付近)
www.slideshare.net
Aurora (InnoDBの亜種)において、それぞれのMTRでアトミックに実行されなければならない変更内容を表しているredoログレコードは、各ログレコードが属するPGによってまとめられ、これらのまとまりはストレージサービスに書き込まれる。
各MTRの最後のログレコードはconsistency(一貫性)ポイントとしてタグ付けされます。( CPLのことですね )
Auroraのライターでは "community" MySQLがサポートしている分離レベルと全く同等のものをサポートしている。
Auroraのリードレプリカは、ライターのトランザクション開始とコミットに関する情報を継続的に取得し、これらの情報を使ってスナップショット分離をサポートしている。
なお、並行性制御は、ストレージサービスに影響がない形で、全てデータベースエンジンに実装されている。
ストレージサービスは、 "community" InnoDBのローカルストレージへのデータを書き込みしたときと論理的に同一の、根本的には同じデータに対して統一されたビューを見せます。
Auroraは、コントロールプレーンにAmazon Relational Database Service(RDS)を活用している。
RDSはデータベースインスタンス上にホストマネージャ(HM)と呼ばれるエージェントを動かしており、クラスタのヘルスチェックを監視し、フェイルオーバーが必要かどうか、あるいはインスタンスを入れ替える必要があるかどうかを判断する。
各データベースインスタンスは、クラスターの中で1台のライターと0台以上のリードレプリカで構成される。
クラスタのインスタンス群は、1つのリージョン(例:us-east-1、us-west-1など)で、通常は異なるAZに配置され、同じリージョンのストレージインスタンス群と接続します。
セキュリティのために、Auroraではデータベース、アプリケーション、ストレージ間の通信を分離している。
実際には、各データベースインスタンスは3つのVPC上で通信することができる。
- ユーザーのアプリケーションがデータベースエンジンとやりとりするCustomer VPC
- データベースエンジンとコントロールプレーンが相互に通信するRDS VPC
- データベースとストレージサービスが相互に通信するStorage VPC
ストレージサービスは、各リージョンの少なくとも3つのAZにまたがってプロビジョニングされたEC2 VMのクラスター上にデプロイされ、複数のユーザーのストレージボリュームの提供、ストレージボリュームからのデータの読み書き、ストレージボリュームからのデータのバックアップとリストアを一括して担当する。
ストレージノードはローカルのSSDを操作し、データベースエンジンインスタンス、他の組となるストレージノード、バックアップ/リストアサービス(変更されたデータを継続的にS3にバックアップ、必要に応じてS3からデータをリストア)と相互にやり取りをします。
クラスターとストレージボリュームの設定、ストレージボリュームのメタデータ、S3にバックアップされたデータの詳細な内容の永続化するために、ストレージのコントロールプレーンとしてAmazon DynamoDBを使っている。
Amazon DynamoDB vs. etcd vs. Redis Comparison
データベースボリュームのリストアや、ストレージノードの障害後の復旧など、長時間実行するタスクのオーケストレーションには、Amazon Simple Workflow Serviceを使っている。
高いレベルの可用性を維持するためには、エンドユーザーに影響がでる前に、実際の問題や潜在的な問題を積極的に自動化して早期に検知することが必要になる。
ストレージ運用におけるクリティカルな部分は、メトリクス収集サービスを使い常に監視がされており、重要なパフォーマンスや可用性のメトリクスに不安材料があればアラームを起こす。