Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databasesを読む(その1 Introduction)
論文はこちらです。
https://www.allthingsdistributed.com/files/p1041-verbitski.pdf
Introduction
最近の分散型クラウドサービスでは、下記2つを実現することで回復力とスケーラビリティを実現するケースが増えている。
- コンピュートをストレージから分離すること
- ストレージを複数のノードにまたがって複製すること
(SpannerとかSQL Server Hekatonとか)
これにより下記のような運用をハンドリングできるようになる。
- 動作不良のホストや到達不可能なホストの置き換え(resilience)
- レプリカの追加(scalability)
- writerからレプリカへのフェイルオーバー(resilience)
- データベースインスタンスのサイズの拡大縮小などの操作(scalability)
resilience -> 回復力 フォールトに対する耐性
scalability -> 負荷の増大に対してシステムが対応できる能力
I/O のボトルネックは従来のデータベースシステムとは変わる。
I/Oはマルチテナントなインスタンス群の複数のノード、複数のディクスに分散できるので、個々のノード、diskの負荷は上がらない。
その代わりに、I/Oを要求するデータベース層とこれらの I/O を実行するストレージ層との間のネットワークがボトルネックになる。
データベースがストレージのインスタンス群に並行で書き込む場合において、ネットワークのボトルネックはpackets per second (PPS) や帯域幅を以上にボトルネックになることがある。
ネットワークパスが応答時間は、外れ値のストレージの性能に引っ張られる(ノード、ディスク、またはネットワークパス)。
並行処理
データベースにおいて、ほとんどの場合はお互いに重なりあって操作が可能だが、いくつかの操作は同期的に処理しなければならない。
同期的な処理の操作においては、ストール(失速)やコンテキストスイッチが発生する。(例としては、データベースのバッファキャッシュのミスによるディスク読み込み。)
読み込み中のスレッドは、読み込みが完了するまで続行できない。
キャッシュの欠落は、新しいページに対応するためにダーティなキャッシュページを強制排除(eviction)してフラッシュするという余分なペナルティが発生する可能性がある。
チェックポイントやダーティページ書き込みなどをバックグラウンド処理にまわすことでこのペナルティの発生を減らすことができるが、ストールやコンテキストスイッチ、リソースの競合を引き起こす可能性もある。
トランザクション
トランザクションコミットも問題の1つ。
1つのコミットしていないトランザションの詰まりが他の処理中のトランザクションを止めることがある。
2相コミット(2PC)のようなプロトコルでコミットを処理することは、クラウドスケールの分散システムでは困難。
(データ指向アプリケーションデザイン 9.4.1参照)
Auroraでの取り組み
大規模なシステムは複数のデータセンターに分散しているため、これらのプロトコルは高レイテンシーになりがち。
これらの問題を解決するために、Aruroaでは、高度に分散したクラウド環境において、redo ログをより積極的に活用した。
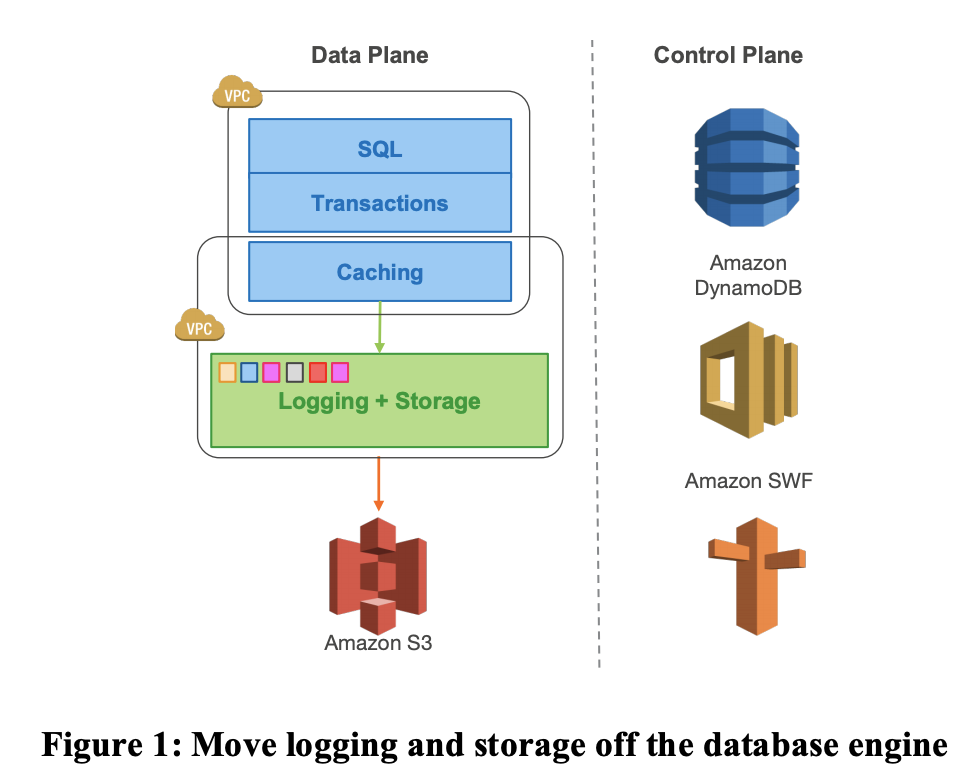
https://www.allthingsdistributed.com/files/p1041-verbitski.pdf より参照
仮想化され、分割されたredoログを抽出して、データベースインスタンス群から疎結合にしたマルチテナントのスケールアウトストレージサービスを使った、新しいサービス指向アーキテクチャ(独立した一つのまとまり的な意味合いくらいに捉えています)になっている。
このAuroraのアーキテクチャの利点は従来のアプローチに比べて3つの利点がある。
独立した耐障害性と自己回復機能を備えた複数のデータセンターにまたがってストレージを構築することで、ネットワーク層またはストレージ層のいずれかでパフォーマンスの変動や一時的または恒久的な障害からデータベースを保護する。
- 耐久性の障害は長期的な可用性イベントとしてモデル化できており、さらに、この可用性イベントは長期的な性能変動としてモデル化できることがわかっています。
- The Tail at Scale – Google Research をもとにして、モデルに沿って検証すればOKっていうことを言いたいのかと思います
redo ログレコードをストレージに書き込むだけで、ネットワークのIOPS(Input/Output Per Second / I/O毎秒)を桁が変わるくらいに削減することができる。
最も複雑で重要な機能のいくつか(バックアップとREDOリカバリ)を、データベースエンジン内の一回限りのコストが掛かる操作から、大規模な分散インスタンス群で補償された連続的な非同期処理に移行する。
- これにより、チェックポイントなしでほぼ瞬時にクラッシュからのリカバリが可能になり、フォアグラウンド処理を妨げないコストが低いなバックアップが可能になった。
本論文では3つの寄与について述べる。
クラウド規模での耐久性をどのように推論するか、また、相関障害に強いクォーラムシステムをどのように設計するかの方法。(セクション2)。
スマートストレージに従来のデータベースの下位4分の1をこの階層にオフロードし活用する方法(セクション3)。
分散ストレージにおける多相同期、クラッシュリカバリ、チェックポイントをなくす方法(セクション4)。
次に、これら3つのアイデアを組み合わせてAuroraの全体的なアーキテクチャを設計する方法をセクション5で紹介し、セクション6ではパフォーマンスの結果をレビューし、セクション7節では学んだことを紹介する。
最後に、セクション8で関連する作業を簡単に調査し、セクション9で結論を述べる。
REFERENCES
https://cs.nyu.edu/~mwalfish/papers/yesquel-sosp15.pdf
https://15721.courses.cs.cmu.edu/spring2018/papers/levandoski-cidr2015.pdf