3. THE LOG IS THE DATABASE
Auroraはセクション2で紹介したように、セグメントに分けられて複製されているストレージシステムになっている。
このようなストレージシステムを使って従来のデータベースを動かすと、ネットワークI/O、同期のストール(失速)の観点で受け入れられないほどのパフォーマンスの負荷がかかる。
セクション3ではその理由を説明する。
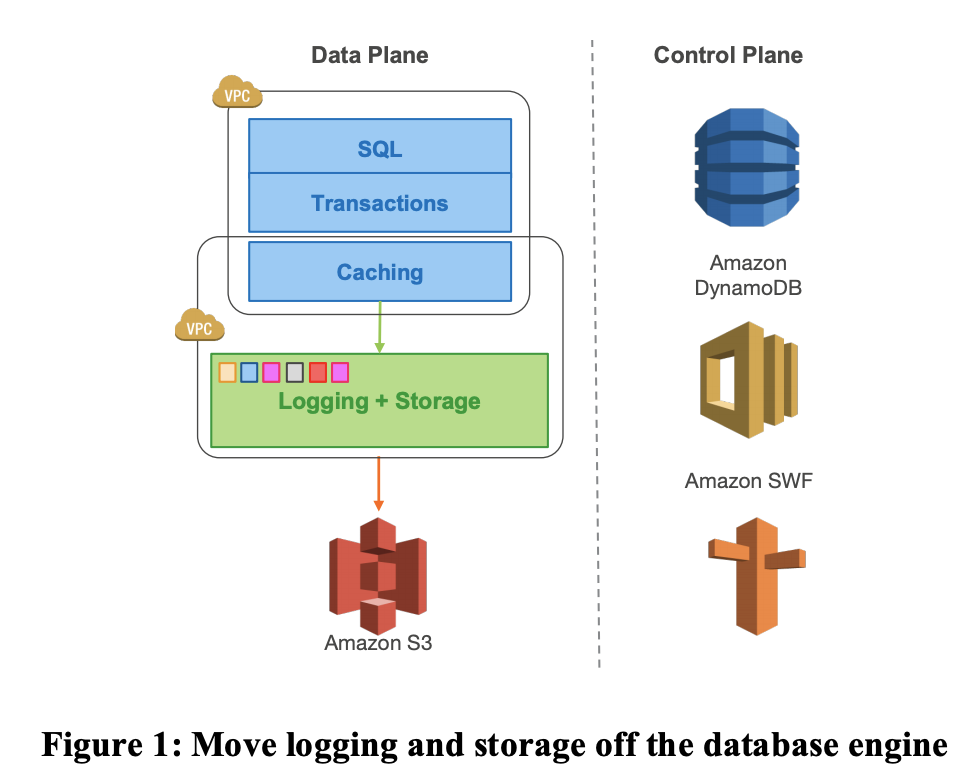
そして、ログ処理をストレージサービスに押し付けるアプローチを説明し、このアプローチがネットワークI/Oを劇的に削減できることを実験的に説明する。
最後に、同期ストールと不要な書き込みを最小化するためにストレージサービスで利用している様々な技術について説明する。
3.1 増幅された書き込みの負荷
ストレージボリュームをセグメント化し、各セグメントは6つに複製され、そのうち4つが書き込みクオラム(4/6)というモデルでは高い回復力が得られる。
しかし、このモデルは、アプリケーションの書き込みごとに多くの異なる実際のI/Oが発生するMySQLのような従来のデータベースだとひどいパフォーマンスの低下を引き起こす。
この高いI/Oボリュームはレプリケーションによって増幅され、PPS(1秒あたりのパケット数)をさらに増加させる。
これらのI/Oは同期の起点になり、パイプラインを停滞させ、レイテンシーを増大させる。
従来のデータベースで書き込みがどのように行われるか見てみる。
MySQLのようなシステムは、データページを公開するオブジェクト(ヒープファイル、Bツリーなど)に書き込むとともに、redoログレコードをWAL(Write-Ahead Log)に書き込む。
各redoログレコードは、変更されたページのビフォアーイメージとアフターイメージの差分で構成される。
ログレコードは、ページのビフォアーイメージに適用され、アフターイメージを生成する。
(データベースシステム 改定2版 p236)
実際には、他にもデータも書き込まなければならない。
例えば、図2に示すように、データセンター間で高可用性を実現し、アクティブ・スタンバイ構成で動作する同期ミラーリングされたMySQLの構成を考えてみる。
AZ 1にアクティブなMySQLインスタンスがあり、Amazon Elastic Block Store (EBS)上にネットワーク接続されたストレージがある。
また、AZ 2にはスタンバイ用のMySQLインスタンスがあり、こちらもEBS上のネットワーク接続されたストレージがある。
プライマリのEBSボリュームへの書き込みは、ソフトウェアミラーリング(レプリケーションのことかな)を使用してスタンバイのEBSボリュームと同期する。
Figure 2(下記)に、データベースエンジンが書き込む必要がある様々なデータの種類を示す。
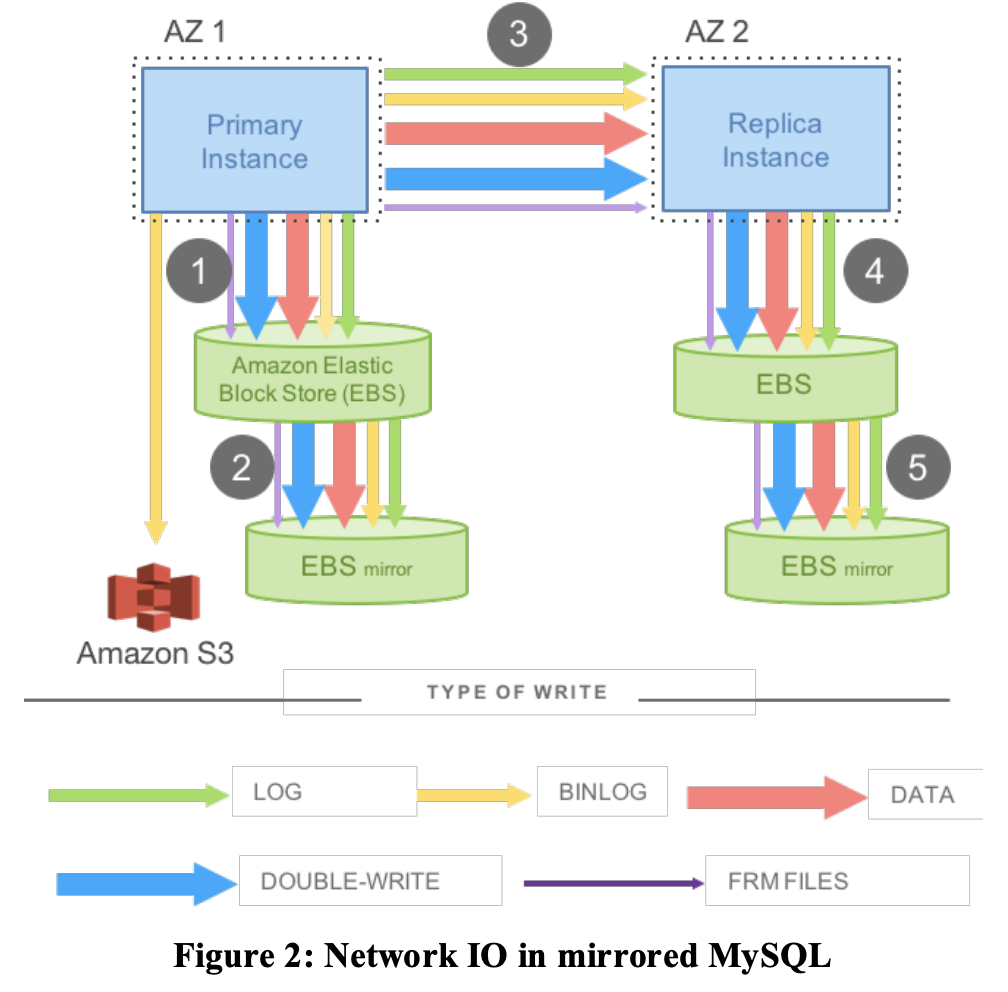
- redoログ
- バイナリ(ステートメントベースを想定)ログ(binログってやつ)
- ページの破損を防ぐためのデータページのダブルライトのための書き込み
- ダブルライトバッファへの書き込み(バッファといいつつ実態はファイル)
- MySQL :: MySQL 8.0 Reference Manual :: 15.6.4 Doublewrite Buffer
- 変更されたデータページ本体
- メタデータ(FRM)ファイル
- MySQL 8以降だとこのファイルなくなるけどどうするんかな
ここらへんの参考資料
koreshiki-nanno.hatenablog.com
また、図2では、実際のI/Oフローの順序を以下のように示している。
ステップ1とステップ2で、EBSに書き込みが発行し、そして今度はAZのローカルミラーに発行し、両者が完了した時点でackを受け取る。
次に、ステップ3では、同期的なブロックレベルのソフトウェアミラーリングによって、スタンバイインスタンスへの書き込みが順次行われる。
最後に、ステップ4と5で、スタンバイインスタンスのEBSとミラーに書き込みが行われる。
このミラーリングするMySQLのモデルは、データを書き込み方法だけでなく、書き込むデータの内容の点からも望ましくない。
ステップ1、3、5は順次的で同期的
- 多くの書き込みに順番があるのでレイテンシがかさむ
- 非同期な書き込みであったとしても、最も遅い動作に律速されるためシステムが外れ値に翻弄され、ジッター(ゆらぎ)が増幅される
- 分散システムの観点からだと、このモデルは4/4の書き込みクオラムを持っているため、障害や外れ値のパフォーマンスに対して脆弱です。
OLTPアプリケーションのユーザー操作は、多くの場合、同じ内容を複数の方法で異なる種類の書き込みを引き起こす
- データ指向アプリケーションデザイン p 97参照、 オンライン トランザクション処理 (OLTP) - Azure Architecture Center | Microsoft Docs
- 例えば、ストレージインフラストラクチャでページが破損しないようにするためのダブルライトバッファへの書き込みなど。
3.2 redo処理をストレージに追い出す
従来のデータベースでは、ページを変更すると、redoログのレコードを生成し、redoログのレコードをページのメモリ上のビフォアーイメージに適用して新しいイメージを生成するログアプリケータ(配布するなにかをさしてそう)を呼び出す。
トランザクションコミットはログを書き込む必要がありますが、ページへの書き込みは非同期に行われることがある。
Auroraでは、ネットワークをまたぐ書き込みはredoログレコードのみとなる。
バックグラウンドの書き込み、チェックポイントのための書き込み、キャッシュのエビクションのための書き込みなど含め、データベース層からもはやページが書き込まれることはない。
その代わりに、ログアプリケータをストレージ層に置いて、そこでバックグラウンドまたはオンデマンドでデータベースのページを生成するようにする。
もちろん、初めからの変更の完全な一連の流れ(ストリームっていってもいいかな)から各ページを1から生成するのは莫大なコストがかかる。
そこで私たちは、データベースのページをバックグラウンドで継続的に実体化(マテリアライズドビューに似ているなにかかな)することで、必要に応じて毎回1からページを再生成することを避ける。
(つまりキャッシュを作っておく。データ指向アプリケーションデザイン p 459あたりを参考)
妥当性、精度の観点から、バックグラウンドでの実体化は完全に任意である。
データベースエンジンの関心としては、ログがデータベース本体であり (the log is the database)、ストレージシステムが実体化するページはログのアプリケーションのキャッシュに過ぎない。
チェックポイントとは異なり、変更の長いチェーンを持つページのみが再実体化が必要があることにも気をつけること。
(データ指向アプリケーション p 521あたりのことを言っていそう)
チェックポイントは、redoログチェーン全体の長さに支配されている。
Auroraのページの実体化は、指定されたページのチェーンの長さに支配されている。
Auroraでのアプローチでは、レプリケーションのための書き込みが増幅しているにもかかわらずネットワーク負荷を劇的に軽減させ、さらに耐久性やパフォーマンスの向上を実現した。
ストレージサービスは、データベースエンジンの書き込みのスループットへの影響を与えることなく、独立して並行(embarrassingly parallel)に実行できる方法でI/Oをスケールアウトすることができる。
Embarrassingly parallelとは? - Qiita
https://www.allthingsdistributed.com/files/p1041-verbitski.pdf より参照
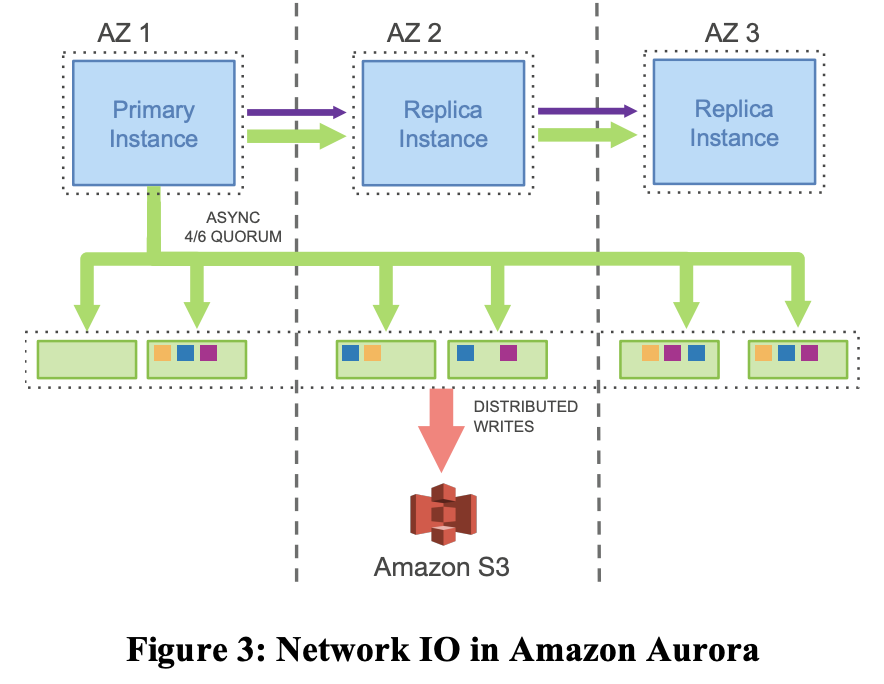
一つの例として、図3にあるような1つのプライマリインスタンスと複数のAZにまたがって配置された複数のレプリカインスタンス(とストレージサービス)を持つAuroraクラスタを考える。
このモデルでは、プライマリは ログレコード( これはredoログか? )をストレージサービスにのみ 書き込み、それらのログレコードとメタデータ更新の内容をレプリカにストリームします。
このI/Oフローは
- 宛先(論理セグメント、ここではPG)に基づいて完全に順序付けられたログレコードをひとまとめにする(バッチ化)
- 各まとまりを6つのレプリカすべてに配信する
- このまとまりはディスク上に永続化される
- データベースエンジンは、6つの複製のうち4つからの確認応答を待つ(書き込みクオラムの安全性を満たし、かつログレコードに永続性があり、書き込まれているかを考慮するため)
レプリカインスタンスは、バッファキャッシュに変更を適用するためにredoログレコードを使用する。
ネットワークI/Oを測定するために、SysBenchの書き込み専用ワークロードを使い、下記の構成で100GBのデータセットを使用してテストを行った。
https://imysql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
それぞれの構成においては、r3.8xlarge EC2インスタンス上で動作するデータベースエンジンに対して30分間テストを行った。
https://www.allthingsdistributed.com/files/p1041-verbitski.pdf より参照
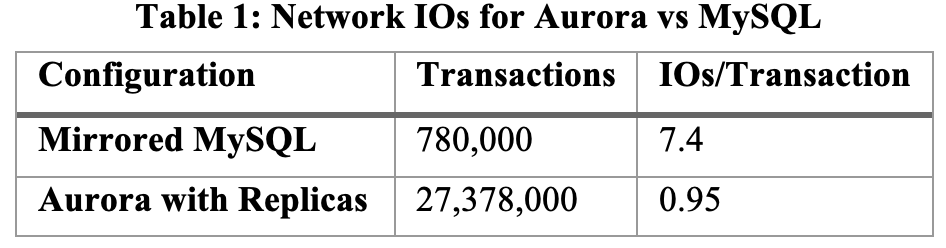
実験の結果は上記のTable 1となった。 (実験の詳細なパラメータ載ってないなあ。。。)
- AuroraのほうがミラーリングMySQLよりも35倍SysBenchのtransactionの値がよかった
- Auroraでのデータベースノード上のトランザクションあたりのI/O数は、ミラーリングMySQLの7.7倍も少ない
- Auroraでは書き込みを6回に増幅させている(6クオラムに書き込み数を合計しているように読み取れる)
- MySQLのEBS内の一連の複製やAZまたぎの書き込みをカウントしていない
- 各ストレージノードは6つの複製のうちの1つにすぎないので、増幅されていない書き込みを見ていることになり、この階層で処理を必要とするI/O数が実質的には1/46になる。(7.7 x 6 = 46.2)
ネットワークを介したデータ書き込みを減らすことで得られるコスト削減により、耐久性と可用性のためにより積極的にデータを複製し、ジッターの影響を最小限に抑えることで並行にリクエストを処理することが実現できた。
また、処理をストレージサービスに移行することで、下記2点より耐久性と可用性の向上が実現できた。
さらにここでクラッシュリカバリーについてみていく。
従来のデータベースでは、クラッシュが発生した後、システムは最新のチェックポイントから開始し、ログを再生して、すべての永続的なredoレコードが適用されていることを確認しなければならない。
Auroraでは、耐久性のあるredoレコードの適用が継続的に、非同期的に、そしてインスタンス群全体に分散してストレージ層で行われる。
いくつかのページの読み込み要求は、ページが最新のものでない場合いくつかのredoレコードの適用が必要になることはある。
したがって、クラッシュリカバリのプロセスはすべての通常のフォアグラウンド処理に分散される。(つまりなんもしなくていいってことかな)
データベースの起動時には何もする必要ない。
3.3 ストレージサービスの設計のポイント
Auroraのストレージサービスの設計方針で重要な思想は、 フォアグラウンドの書き込み要求の待ち時間を最小化 することである。
ストレージ処理の大部分をバックグラウンドに移行した。
ストレージ層からのフォアグラウンドのリクエストのピークから平均までの変動を普通に考えると、フォアグラウンドのパスの外でこれらのタスク(ストレージ処理のことかな)を実行するための十分な時間がある。
CPU(の処理)とディスク(I/O)を入れ替えることもあります。
例えば、ストレージノードがフォアグラウンドの書き込み要求の処理(CPU側)で忙しいときに、disk容量にまだ余裕があれば古いページのバージョンのガベージコレクション(GC)を実行する必要はない。
Auroraでは、バックグラウンド処理とフォアグラウンド処理は負の相関関係を持っている。(つまりバックグラウンドの処理が増えればフォアグラウンドの処理は減る、vice versa)
これとは反対に、従来のデータベースはページのバックグラウンド書き込みやチェックポイント処理がシステムのフォアグラウンド処理と正の相関関係を持つ。
Auroraではシステム上にバックログが蓄積した場合、長いキューの蓄積を防ぐためにフォアグラウンド処理の制限を行う。
セグメントはシステム内の様々なストレージノードに高エントロピー(バラバラ度が高いってことかな)で配置されているため、1つのストレージノードでの制限は4/6のクオラム書き込みによって簡単に処理され、一つの低速なノードのように見える。
ストレージノード上の様々なアクティビティをより詳細に見てみる。
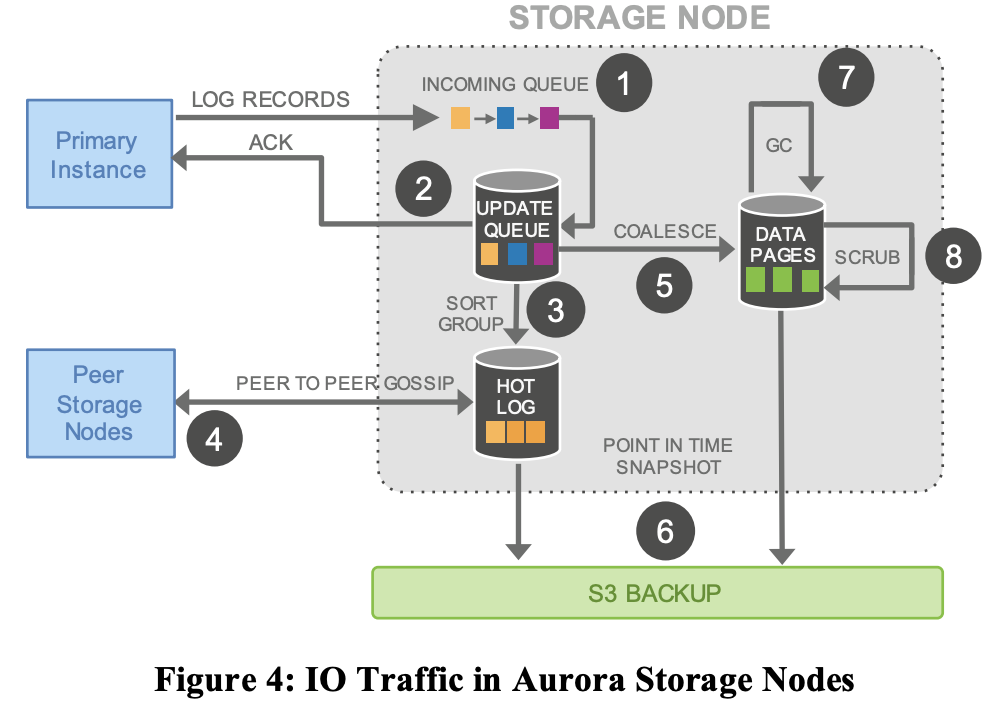
https://www.allthingsdistributed.com/files/p1041-verbitski.pdf より参照
Figure 4に示すように、以下のステップが含まれる
- ログレコードを受信し、インメモリキューに追加する。
- ディスクにレコードを永続化させて、ackする。
- バッチによってはロストする可能性があるのでレコードを整理し、ギャップがないか確認する。
- ノード間でやり取り(godsip protocol)してギャップを埋める。
- ログレコードを新しいデータページと結合させる
- 定期的にステージログと新ページをS3に送る
- 古いバージョンを定期的にガベージコレクションする
- ページのCRCコードを定期的に検証する
上記の各ステップは非同期的であるだけでなく、1と2のステップのみフォアグラウンドパスにあり、レイテンシに影響を与える可能性があることに注意。