継続的デリバリー(CD)とはなにか?
根本は アジャイル宣言の背後にある原則 になるかと思います。
顧客満足を最優先し、価値のあるソフトウェアを早く継続的に提供します。
Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
agilemanifesto.org から引用
書籍 継続的デリバリー でもこの部分を引用して本のタイトルをつけたと書いてあります。
さらにClean Agileからも引用してみます。
変更するたびに本番環境にコードをリリースするプラクティス
Clean Agile p88より
なるほど、わかりやすい。
Continuous Delivery Foundation (CDF)の定義も見てみます。
CD is a software engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time.
CDは、チームが短いサイクルでソフトウェアを生産し、いつでも確実にソフトウェアをリリースできるようにするソフトウェアエンジニアリングのアプローチです。
github.com
コード、ソフトウェアという言葉が多く見受けられるが、データのリリースはどうなのだろうか?という疑問が若干わきます。
自分の中では価値を提供する変更のデリバリーであれば全部含むという認識でいるので、データのリリースも含めて考えます。
(ゲームでいうマスターデータとかの話)
継続的にという言葉の通り連続することが重要なのですが、それぞれの間隔を長くすることは無意味なので、デリバリーする間隔を短くするプラクティスということが暗黙的にあります。
コードの変更から本番環境へのリリースの間隔を短くしていく取り組みとも言えます。
なぜCDを行うのか?
リリースの間隔が短くリリース頻度が多いチームは逆のチームに比べて、平均修復時間が小さいこと、変更失敗率が低いことが調査でわかっています。
下記を参照のこと
www2.slideshare.net
speakerdeck.com
LeanとDevOpsの科学
ここで注目したいのは、加速化を推進してもパフォーマンス改善以外の項目に対してトレードオフが発生しないということです。(LeanとDevOpsの科学 p27あたり)
リリースを頻繁に行うためには、下記の取り組みが必要になってきます。
- リリースに伴う各ステップのリードタイムを短くする
- リリース単位を小さくする
これらの取り組みの結果、最終的にパフォーマンスがよくなります。
CDを行うための準備
プロセスを整理する
コードの変更、コードのpush、テスト、PR、マージ、deployのstepにおいて、どのような処理を行うのかなどを整理し、自動化をできるように整備します。
自動化の取り組み
継続的にそして、素早くデリバリするために各ステップの自動化は必須です。
自動化としては下記が挙げられると思います。
- ユニットテストの自動化
- ビルドの自動化
- 受け入れテストの自動化
- リリースの自動化
現状の分析
構成管理やリリース管理の成熟度
継続的デリバリー p487 に成熟とのレベルの定義があるのでこれで分析してみましょう
レベル3 : 最適化 プロセスの改善に注力する
レベル2 : 定量的な管理 プロセスが計測可能で制御されている
レベル1 : 一貫している 自動化されたプロセスがアプリケーションのライフサイクルに適用される
レベル0 : 繰り返し可能 プロセスは文書化され、一部は自動化されている
レベル-1 : リグレッションエラー多発 プロセスは繰り返せず管理も貧弱、そして対処療法を行っている
これらを使って分析し、step by stepで対応していくのがよいでしょう。
自分のプロジェクトを分析した結果を残しておきます。
| プラクティス |
ビルド管理および
継続的インテグレーション |
テスト |
データ管理 |
環境およびデプロイメント |
| |
レベル2
ビルドメトリクスを収集して可視化し、
それに基づいて作業する。
ビルドを壊れたままにしない |
レベル2くらい
本番環境への変更の取り消しは滅多に発生しない
問題があればすぐに見つかり、すぐに修正される。
非機能要件の定義は甘い
受け入れテストは自動化されていない。 |
レベル2くらい
データベースの更新やロールバックはデプロイのたびにテストされる。
データベースのパフォーマンスを管理、最適化する。 |
レベル1くらい?
一部の環境ではデプロイを自動化する。
新しい環境は手軽に作成する。
全ての構成情報を外に出してバージョン管理できてる
全ての環境に対して同じ手順でデプロイする
ボタンを押すだけでは完結していない。。 |
今できてないことは、受け入れテストの自動化、デプロイメントの自動化になります。
自分たちの課題の分析
受け入れテストの自動化
QAチームで今は手動テストを行っている。
シフトレフトしていきたいが取り組みとしては滞っている。
機能テストをよりリッチにしていくなども考えている。
受け入れテストの自動化ができていないことがデプロイの自動化に踏み込めない原因でもある
デプロイの自動化
本番環境へのデプロイ環境への自動化はできていない。(検証環境はできている)
手順はこんな感じでやっている
- Docker imageはmasterにmergeされると全部buildされてpushされている
- QAはどのimageを使うかを選んで反映しておく。
- QAチームからサインオフがでる
*ここでDocker imageのハッシュ値が決まる
- 本番環境のdeployサーバーにsshする
- deployコマンドを打つ
- この中で DB schemaの変更を行う専用のPodのimageを先に更新して、このPodに入ってスクリプトと叩く
- kubectl apply(をラップしたコマンド)でimageを更新を含むkubernetesの更新を行う。
自動化できていない原因は下記の通り
受け入れテストの整備
反映後の受け入れテストの自動テストが整備されていないため切り戻しが自動でできない。
DBのschemaアプライ
DB schemaのアプライが同期的に実行できない場合もあるので、ここを順々に実行する方法を探している
だた、基本的には後方互換性を担保して開発しているので問題が起きにくい状態ではある。。
監査、RBAK
特に操作ログの保持が難しい。(改ざんをどう防ぐかとか)
このような分析をもとに次につなげていく。
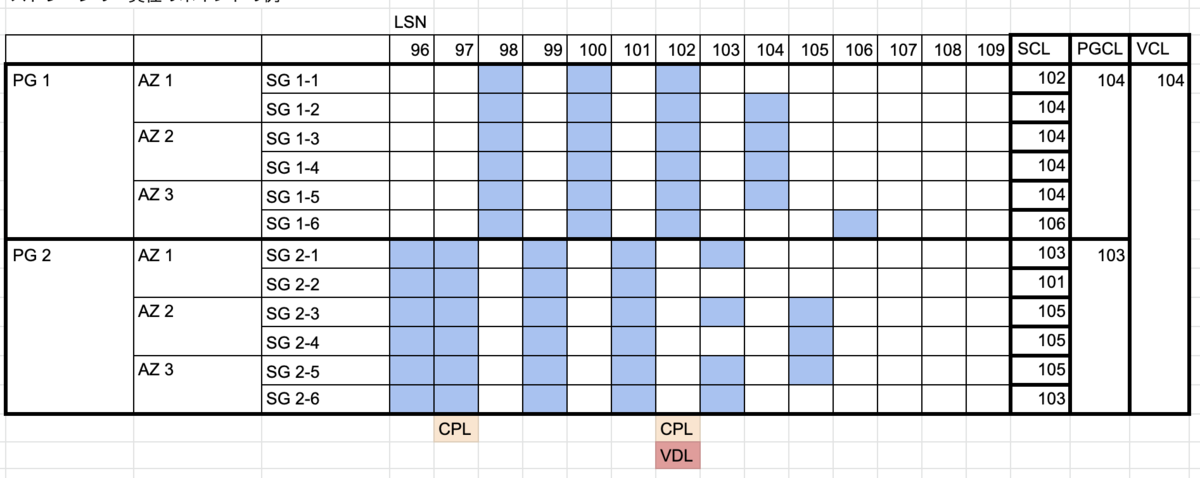
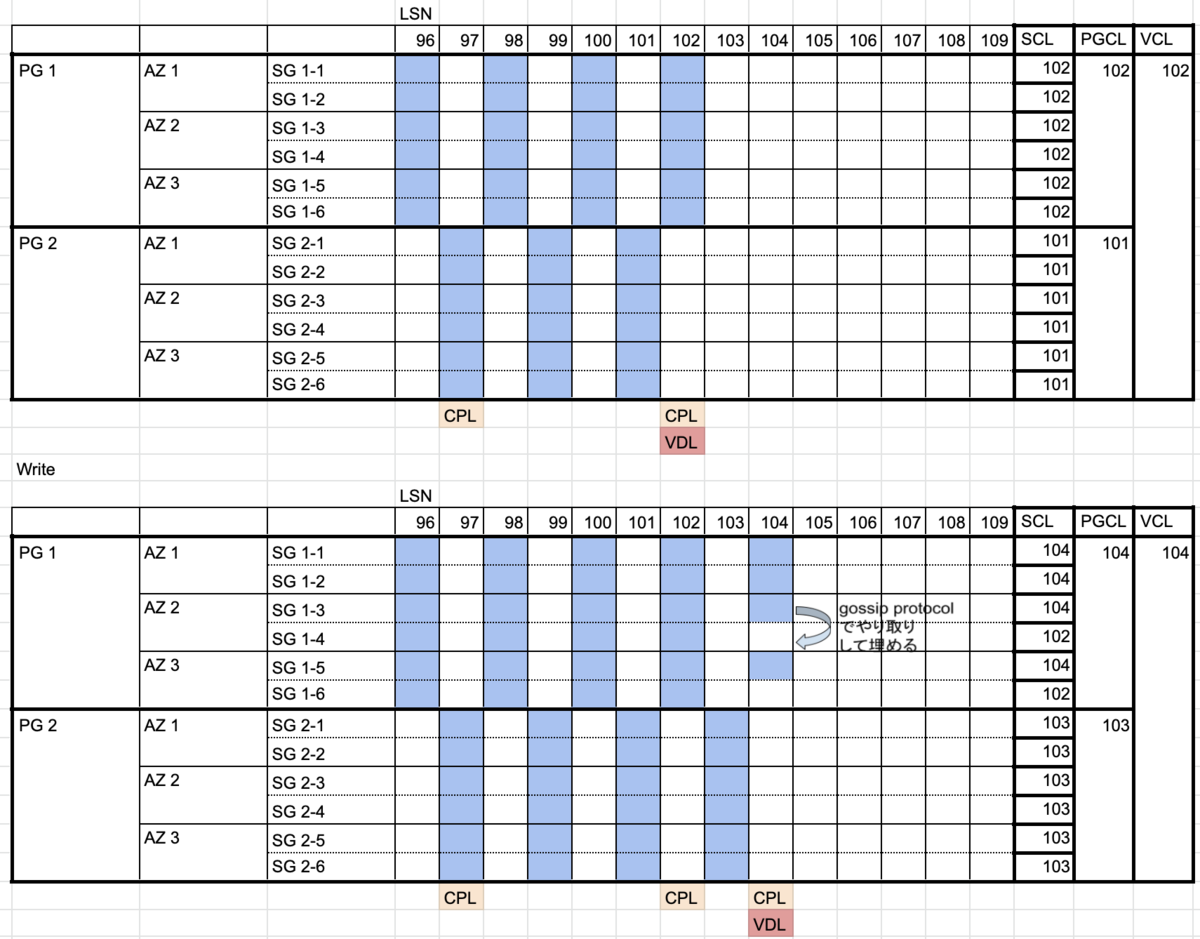
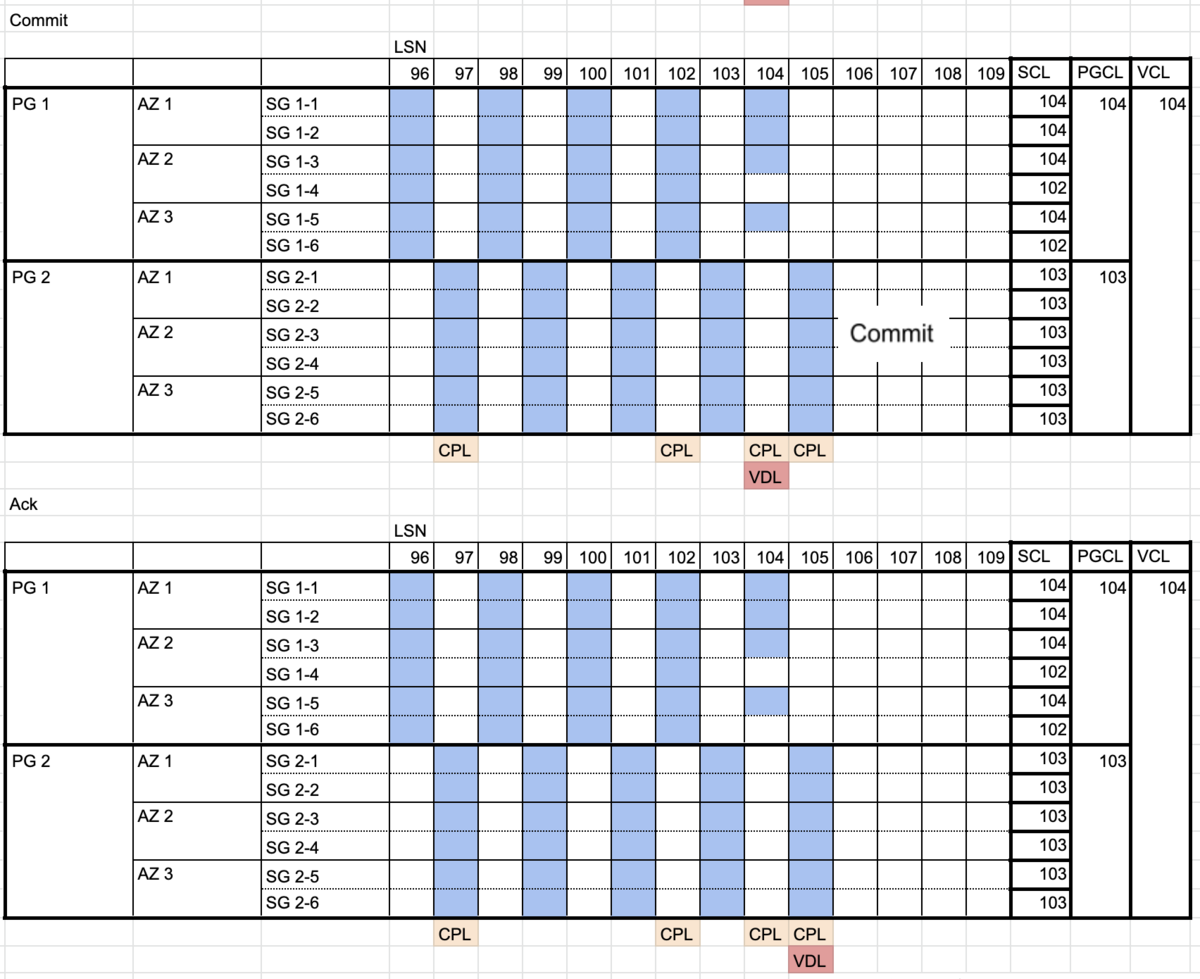
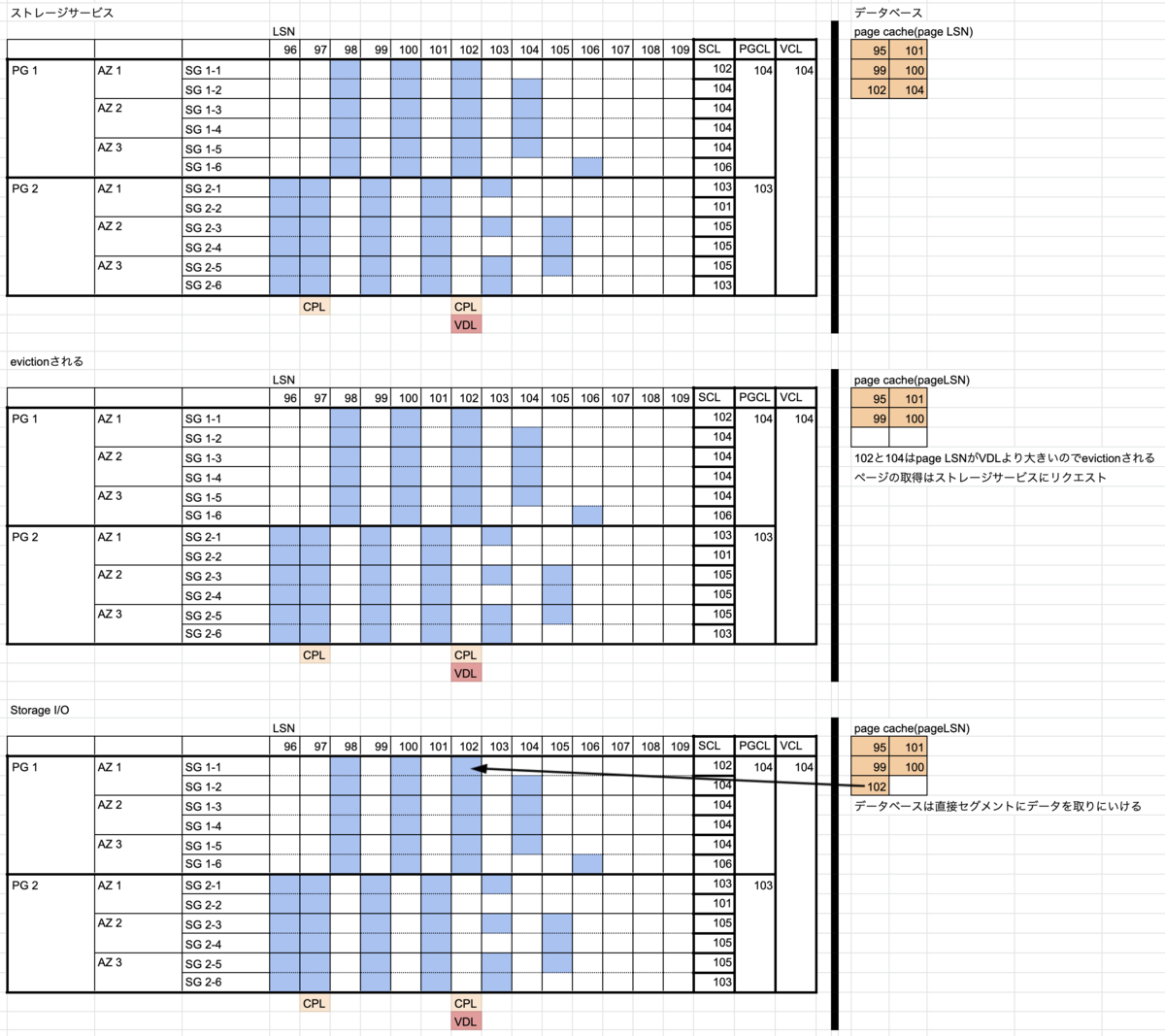
さらに少し考えてみた
大規模サービスにおいて、継続的デリバリをするのであれば、継続的デリバリの中からデータベースの管理は切り離さないとだめだと思う。
データベースのバージョン管理はしつつ、デリバリする際にバージョンが該当のものでなければ止めるという制御を入れる。
ALTERとかカラム追加で時間がダウンタイムが発生する場合、デリバリするタイミングで気がつくとそれはもう手遅れなので前もって気がつくのがいいが、デリバリを止められる仕組みさえあればいい。
と考えてみたが、継続的デリバリ12章に理想が書いてあった。。
受け入れテストまで整備するべきかどうかもあるけど、正直エラーがあったら切り戻すで割り切らないと多分一生できん気がする